Overview
In Spark, using Future is a way to achieve concurrency, allowing multiple tasks to be executed simultaneously instead of sequentially. This is especially helpful when performing multiple queries concurrently without blocking the main thread.
In this code, I was addressing the question: "How can I run SQL queries in parallel in Spark using Scala?" I utilized Future to enable asynchronous execution. With Future, I could initiate both SQL queries without waiting for one to finish before starting the other, making the process more efficient.
Approach and Code Explanation
Here’s the steps I took in the code:
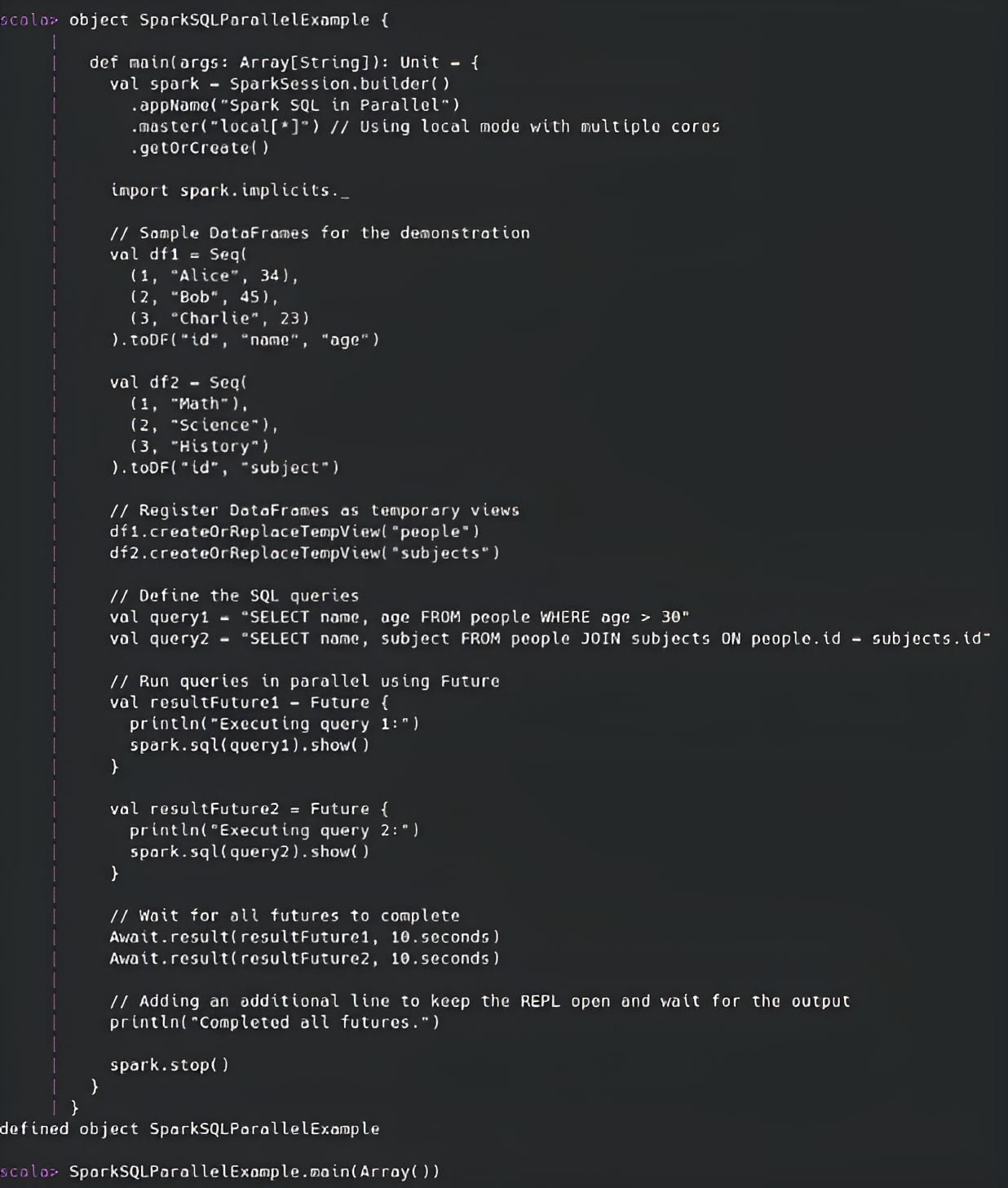
- Spark Session Setup: I initialized a
SparkSessionto interact with Spark. - Creating DataFrames: I created two DataFrames,
df1anddf2, representing data about people and subjects. - Creating Temp Views: I registered these DataFrames as temporary views, named
peopleandsubjects, to be used in SQL queries. - SQL Queries: Two SQL queries were defined:
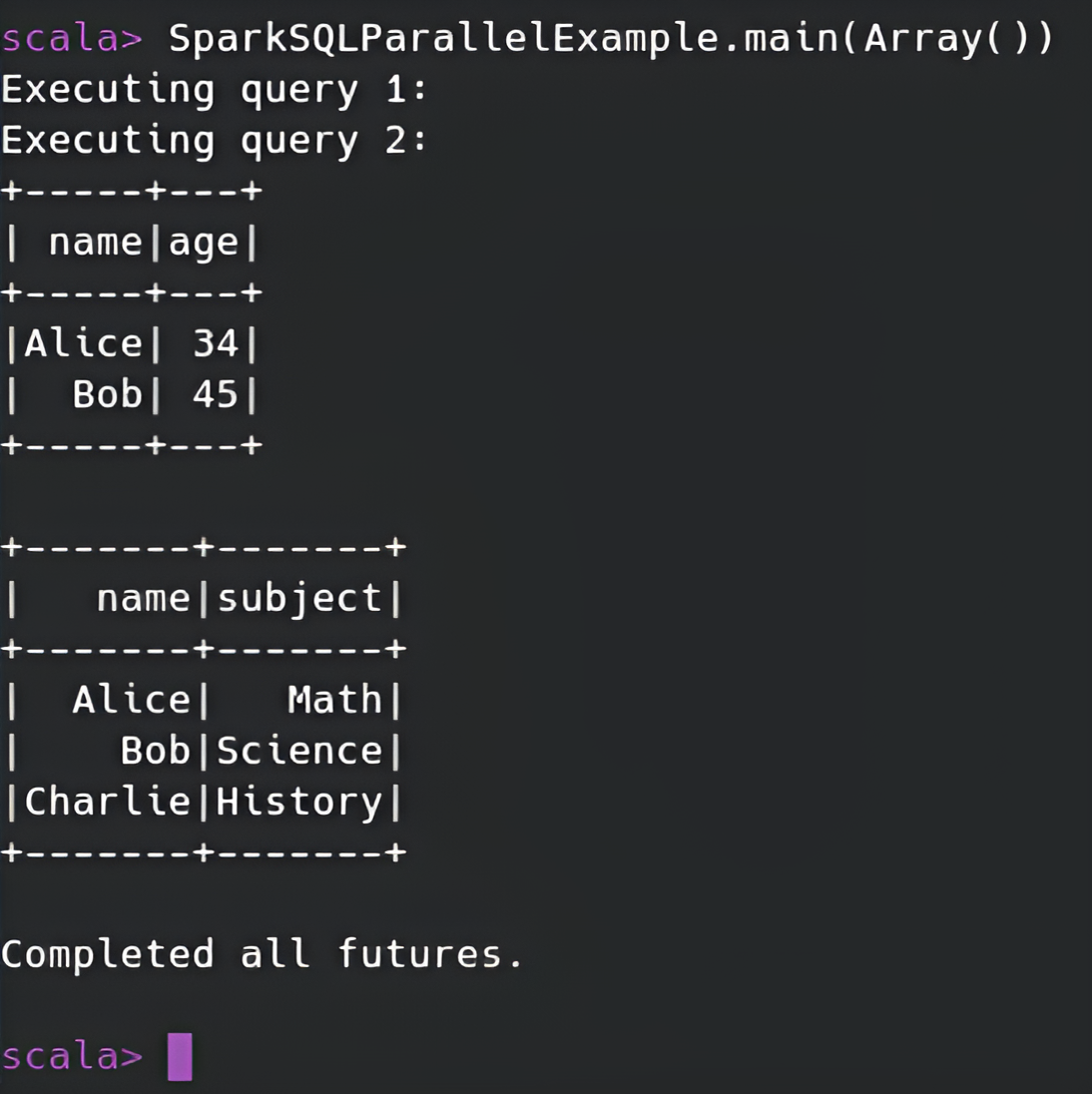
Query 1:Selects names and ages of people older than 30.Query 2:Joins thepeopleandsubjectstables and selects names and subjects.
- Running Queries in Parallel: I wrapped each query inside a
Future, allowing both queries to be executed concurrently. - Waiting for Completion: I used
Await.resultto block the main thread until both futures completed, ensuring that the program doesn’t exit prematurely. - Spark Cleanup: After completing the queries, I stopped the Spark session to release the resources.
// Scala code example
val spark = SparkSession.builder.appName("Future Example").getOrCreate()
// DataFrames
val df1 = spark.read.option("header", "true").csv("people.csv")
val df2 = spark.read.option("header", "true").csv("subjects.csv")
// Register Temp Views
df1.createOrReplaceTempView("people")
df2.createOrReplaceTempView("subjects")
// Future for Query 1
val query1Future = Future {
spark.sql("SELECT name, age FROM people WHERE age > 30").show()
}
// Future for Query 2
val query2Future = Future {
spark.sql("SELECT p.name, s.subject FROM people p JOIN subjects s ON p.id = s.person_id").show()
}
// Wait for both queries to complete
Await.result(query1Future, Duration.Inf)
Await.result(query2Future, Duration.Inf)
spark.stop()
Visuals
Below are images representing the codes and results during the execution of the Spark SQL queries: