Introduction
In distributed computing, data is processed across multiple machines. A key concept is distributing the data, and Apache Spark is a tool that helps do this efficiently. Spark can handle large datasets by processing them in parallel across many machines. To use Spark, you need to represent your data as a Resilient Distributed Dataset (RDD).
Word Count Program Implementation
One common way to create an RDD in Spark is by using the parallelize function, which is part of SparkContext. In this example, we'll explore how we can implement a basic word count program using Apache Spark and Scala. The goal is to process a list of input strings to count the occurrences of each word.
Steps Taken
- Created a SparkSession: First, I initialized a SparkSession, the main entry point to use Spark and its features, including SparkContext.
- Prepared the Input Data: I passed a list of sentences (as arguments in the main method) that I wanted to analyze and count words from.
- Created an RDD: I used
spark.sparkContext.parallelize(input)to convert the list into an RDD. This allows Spark to handle the data in a distributed manner, splitting it into smaller parts to be processed in parallel. - Transformed the RDD: Applied transformations like
flatMap,map, andreduceByKeyto analyze the data. - Collected and Printed the Results: The final results were collected using
collect()and printed usingforeach(println). - Stopped the SparkSession: Stopped the SparkSession to free up resources after processing the data.
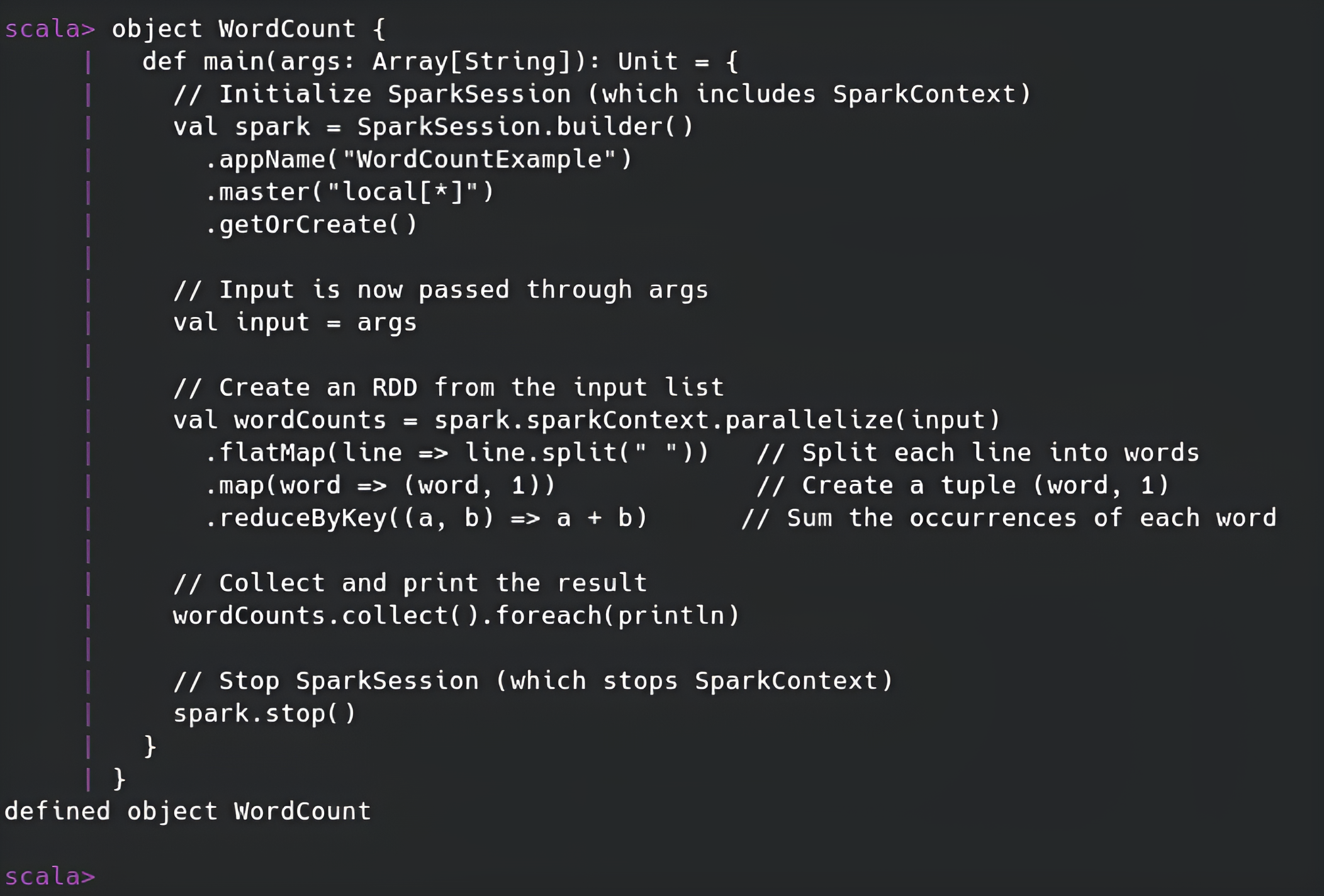
Code Implementation
// Import SparkSession class
import org.apache.spark.sql.SparkSession
object WordCount {
def main(args: Array[String]): Unit = {
// Initialize SparkSession (which includes SparkContext)
val spark = SparkSession.builder()
.appName("WordCountExample")
.master("local[*]")
.getOrCreate()
// Input is now passed through args
val input = args
// Create an RDD from the input list
val wordCounts = spark.sparkContext.parallelize(input)
.flatMap(line => line.split(" ")) // Split each line into words
.map(word => (word, 1)) // Create a tuple (word, 1)
.reduceByKey((a, b) => a + b) // Sum the occurrences of each word
// Collect and print the result
wordCounts.collect().foreach(println)
// Stop SparkSession (which stops SparkContext)
spark.stop()
}
}
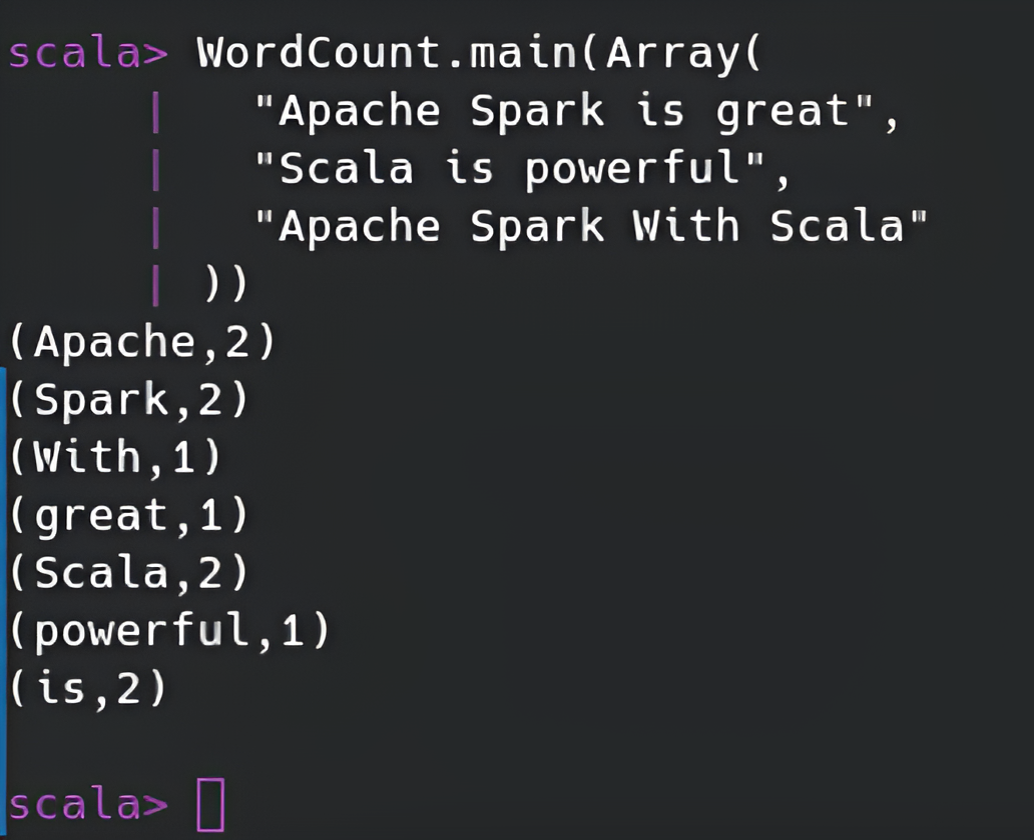
// To run WordCount.main() explicitly with input:
WordCount.main(Array(
"Apache Spark is great",
"Scala is powerful",
"Apache Spark With Scala"
))
Visuals